Please consider supporting us by disabling your ad blocker. Thank you for your support.
Please consider supporting us by disabling your ad blocker.
Image Classification with Python, TensorFlow and Deep Learning

In this tutorial, we will tackle the Fashion MNIST dataset to train a neural network that will classify images of clothing.
The dataset contains 70,000 grayscale images of 28 × 28 pixels each in 10 categories.
The Fashion MNIST dataset is a drop-in replacement of the MNIST dataset which gives us a more challenging problem than the MNIST digit recognition dataset.
The image below shows a sample from the Fashion MNIST dataset:

Import the Dataset Using Keras
Let's load Fashion MNIST using Keras:
from tensorflow import keras
fashion_mnist = keras.datasets.fashion_mnist
(X_full, y_full), (X_test, y_test) = fashion_mnist.load_data()The dataset contains 60,000 images for training the network and 10,000 images for testing.
X_full and y_full represent the training set, and X_test and y_test represent the test set.
The images are represented as 28 x 28 arrays with pixel intensities ranging from 0 to 255.
Exploration and Preprocessing
Let's take a look at the data that we loaded. The training set contains 60,000 training images represented as 28 x 28 Numpy arrays and 60,000 labels.
The test set contains 10,000 training images represented as 28 x 28 Numpy arrays and there are 10,000 corresponding labels:
X_full.shape, y_full.shape
>>> ((60000, 28, 28), (60000,))
X_test.shape, y_test.shape
>>> ((10000, 28, 28), (10000,))The dataset is already split into a training set and a test set but we also want a validation set, so let's create one. We also need to scale the input features to a range of 0 to 1 before training the neural network. For that, we will simply divide the pixels values by 255.0:
X_valid, X_train = X_full[:5000] / 255.0, X_full[5000:] / 255.0
y_valid, y_train = y_full[:5000], y_full[5000:]
X_test = X_test / 255.0Here we took the first 5000 images from the training set to create the validation set; the remaining 55,000 images will form the training set.
The labels are integers ranging from 0 to 9 and each integer corresponds to a class name. Here is the list of class names:
class_names = ["T-shirt/top", "Trouser", "Pullover", "Dress", "Coat",
"Sandal", "Shirt", "Sneaker", "Bag", "Ankle boot"]
So, for example, the first image in the training set represents a coat:
class_names[y_train[0]]
>>> 'Coat'Building the Model Using the Sequential API
We are now ready to build the neural network:
from tensorflow.keras import layers
model = keras.Sequential([
layers.Flatten(input_shape=[28, 28]),
layers.Dense(128, activation="relu"),
layers.Dense(64, activation="relu"),
layers.Dense(10, activation="softmax"),
])We start by creating a Sequential model which is appropriate for a plain stack of layers.
The first layer in this network is a Flatten layer whose role is to convert each image from a two-dimensional array (28 x 28 pixels) into a one-dimensional array (784 pixels).
Next, we have a sequence of two fully connected Dense layers with 128 neurons and 64 neurons (or nodes) respectively. They will use the ReLu activation function.
Finally, we have a Dense output layer with 10 neurons (one for each of the labels) using the softmax activation function which will give us our actual output class label probabilities.
Instead of passing a list of layers when creating the Sequential model as we did, we can add the layers incrementally via the add() method:
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=[28, 28]))
model.add(keras.layers.Dense(128, activation="relu"))
model.add(keras.layers.Dense(64, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))We can use the model's summary() method to display all the model's layers along with their parameters and shapes:
model.summary()output:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
_________________________________________________________________
dense (Dense) (None, 128) 100480
_________________________________________________________________
dense_1 (Dense) (None, 64) 8256
_________________________________________________________________
dense_2 (Dense) (None, 10) 650
=================================================================
Total params: 109,386
Trainable params: 109,386
Non-trainable params: 0
_________________________________________________________________The summary also displays the total number of parameters, including trainable and non-trainable parameters.
With a total of 109.386 parameters, the network has quite a lot of flexibility to fit the training data. This doesn't mean that the greater the parameters the network has the better it will be, because, with a lot of flexibility, the network is more susceptible to overfitting the training data.
We can also generate an image of the model using keras.utils.plot_model():
keras.utils.plot_model(model, show_shapes=True)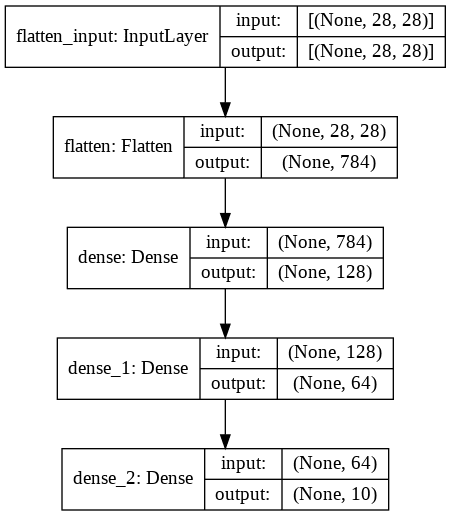
The model's layers are accessible via the layers attribute:
model.layersoutput:
[<keras.layers.core.Flatten at 0x7f0849ff5c50>,
<keras.layers.core.Dense at 0x7f084a7e2990>,
<keras.layers.core.Dense at 0x7f0849faa190>,
<keras.layers.core.Dense at 0x7f0849faa650>]Since model.layers return a list, we can fetch a layer by its index:
layer = model.layers[2]
layer.name
>>>'dense_1'Compiling the Model
After the model is created and before starting the training we need to compile the model using its compile() method to add:
- a loss function that will compare the desired output and the actual output of the network to gives us a measure of the accuracy of the model during training.
- an optimizer which is an algorithm that the model uses to update its parameters and minimize the loss function.
- (optionally) a list of metrics to monitor the training and testing steps.
model.compile(loss=keras.losses.SparseCategoricalCrossentropy(), # equivalent to "sparse_categorical_crossentropy"
optimizer=keras.optimizers.SGD(), # equivalent to "sgd"
metrics=[keras.metrics.SparseCategoricalAccuracy()]) # equivalent to "accuracy"Training and Evaluating the Model
To start training we simply need to call the model's fit() method. This will "fit" the model to the training data.
epochs = 20
history = model.fit(X_train, y_train, epochs=epochs,
validation_data=(X_valid, y_valid))output:
Epoch 1/20
1719/1719 [==============================] - 5s 2ms/step - loss: 0.7695 - sparse_categorical_accuracy: 0.7424 - val_loss: 0.5365 - val_sparse_categorical_accuracy: 0.8162
Epoch 2/20
1719/1719 [==============================] - 4s 2ms/step - loss: 0.5085 - sparse_categorical_accuracy: 0.8223 - val_loss: 0.4598 - val_sparse_categorical_accuracy: 0.8444
[...]
Epoch 19/20
1719/1719 [==============================] - 4s 2ms/step - loss: 0.2961 - sparse_categorical_accuracy: 0.8942 - val_loss: 0.3189 - val_sparse_categorical_accuracy: 0.8838
Epoch 20/20
1719/1719 [==============================] - 4s 2ms/step - loss: 0.2913 - sparse_categorical_accuracy: 0.8947 - val_loss: 0.3167 - val_sparse_categorical_accuracy: 0.8850We feed the model with the training data: the input features (X_train) and the target classes (y_train). We also set the number of epochs to 20. The validation set is optional but useful to see how well the model performs on each epoch.
We can see that the model reaches an accuracy of 89.47% on the training set and 88.50% on the validation set after 20 epochs.
The history variable is an object containing useful information about the training, like the loss and metrics that were measured at the end of each epoch. We can use it to plot the learning curves.
import matplotlib.pyplot as plt
accuracy = history.history['sparse_categorical_accuracy']
val_accuracy = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(10, 7))
plt.plot(range(epochs), accuracy, "r", label="Training Accuracy")
plt.plot(range(epochs), val_accuracy, "orange", label="Validation Accuracy")
plt.plot(range(epochs), loss, "b", label="Training Loss")
plt.plot(range(epochs), val_loss, "g", label="Validation Loss")
plt.legend(loc="lower left")
plt.gca().set_ylim(0, 1)
plt.grid(True)
plt.show()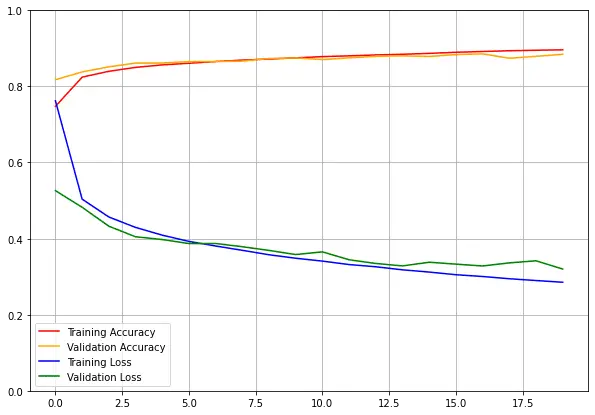
Both the training accuracy and the validation accuracy are increasing after each epoch, meanwhile, the training loss and the validation loss decrease. Perfect.
There is not a big gap between the training accuracy and the validation accuracy, so we can say that the model didn't overfit the training set.
Now its time to evaluate the model on the test set to estimate the generalization error:
model.evaluate(X_test, y_test)output:
313/313 [==============================] - 0s 2ms/step - loss: 0.3549 - sparse_categorical_accuracy: 0.8736
[0.35491448640823364, 0.8736000061035156]Making Predictions with the Trained Model
Now that the model is trained, we can use its predict() method to make predictions on new instances.
# We will use the test set to make predictions
X_new = X_test
y_proba = model.predict(X_new)
# the predictions for the first image in the test set
y_proba.round(2)[0]
>>> array([0. , 0. , 0. , 0. , 0. , 0.01, 0. , 0.06, 0. , 0.92],
dtype=float32)For each instance in the training set the model estimate 10 probabilities (one probability per class). This represents the model's "confidence" to which category the image corresponds.
In this example, the model predicted class 9 (Ankle boot) with a 92% probability which is the class that has the highest probability (the probabilities of the other classes are negligible).
We can use np.argmax() to take the class with the highest probability:
import numpy as np
y_pred = np.argmax(y_proba, axis=1)
y_pred
>>> array([9, 2, 1, ..., 8, 1, 5])
np.array(class_names)[y_pred[0]]
>>> 'Ankle boot'So the model predicted that this image is an Ankle boot (class_names[9]). Let's see if the model classified the image correctly:
y_true = y_test[:1]
y_true
>>> array([9], dtype=uint8)
np.array(class_names)[y_true]
>>> array(['Ankle boot'], dtype='<U11')
As you can see, the model classified this image correctly.
Below you can see some images with their predictions. Incorrect prediction labels are red:
rows = 4
cols = 5
plt.figure(figsize=(13, 15))
for row in range(rows):
for col in range(cols):
index = cols * row + col
plt.subplot(rows, cols, index + 1)
plt.imshow(X_test[index], cmap="binary")
plt.axis('off')
color = 'black'
# if the prediction was incorrect we change the text color
if y_pred[index] != y_test[index]:
color = 'red'
plt.title(f"Prediction: {class_names[y_pred[index]]} \nTrue class: {class_names[y_test[index]]}",
color=color)
plt.show()
Further Reading
If you want to learn more about deep learning and computer vision I recommend the following resources:
Please note that these links are affiliate links, meaning I get a commission if you decide to make a purchase through my links, at no cost to you.
- Part 1 Chapter 3 from the book Deep Learning with Python
- Chapter 10 from the book Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow
- Basic classification: Classify images of clothing from the TensorFlow platform
Summary
In this tutorial, I showed you how to train a simple neural network on the Fashion MNIST dataset using Python, Keras, and TensorFlow.
After 20 epochs of training, the model reaches an accuracy of about 87% on the test set. Not bad at all!
In the next blog posts, we will see how to get a more high accuracy using a convolutional neural network. We will also discuss some techniques to prevent overfitting.
Sounds exciting, right? So don't forget to subscribe to the mailing list to be notified about new posts.
The final code used in this tutorial is available in Colaboratory at this link.
Previous Article
How to Crop Images with OpenCV and Python
Next Article

Control a Smart Device using Tuya API and Python
Hi Fernando, Thank you for introducing yourself. Nice to meet you. I am from Algeria and I'm also interested in technologies. Thank you for the positive feedback. I really appreciate this. Happy learning :)
Oct. 17, 2021, 12:07 a.m.
Hello dontrepeatyourself.org administrator, Your posts are always well-supported by facts and figures.
Feb. 16, 2023, 5:49 p.m.
Thank you Tahlia :)
Feb. 16, 2023, 8:48 p.m.
Oct. 16, 2021, 11:34 p.m.